
dispersed repeats 分析
打开网站
使用在线网站Reputer(BiBiServ2 - REPuter (uni-bielefeld.de))进行散在重复序列分析。
点击Submission。
上传文件
点击upload上传fasta文件,其他的参数保持默认就行。
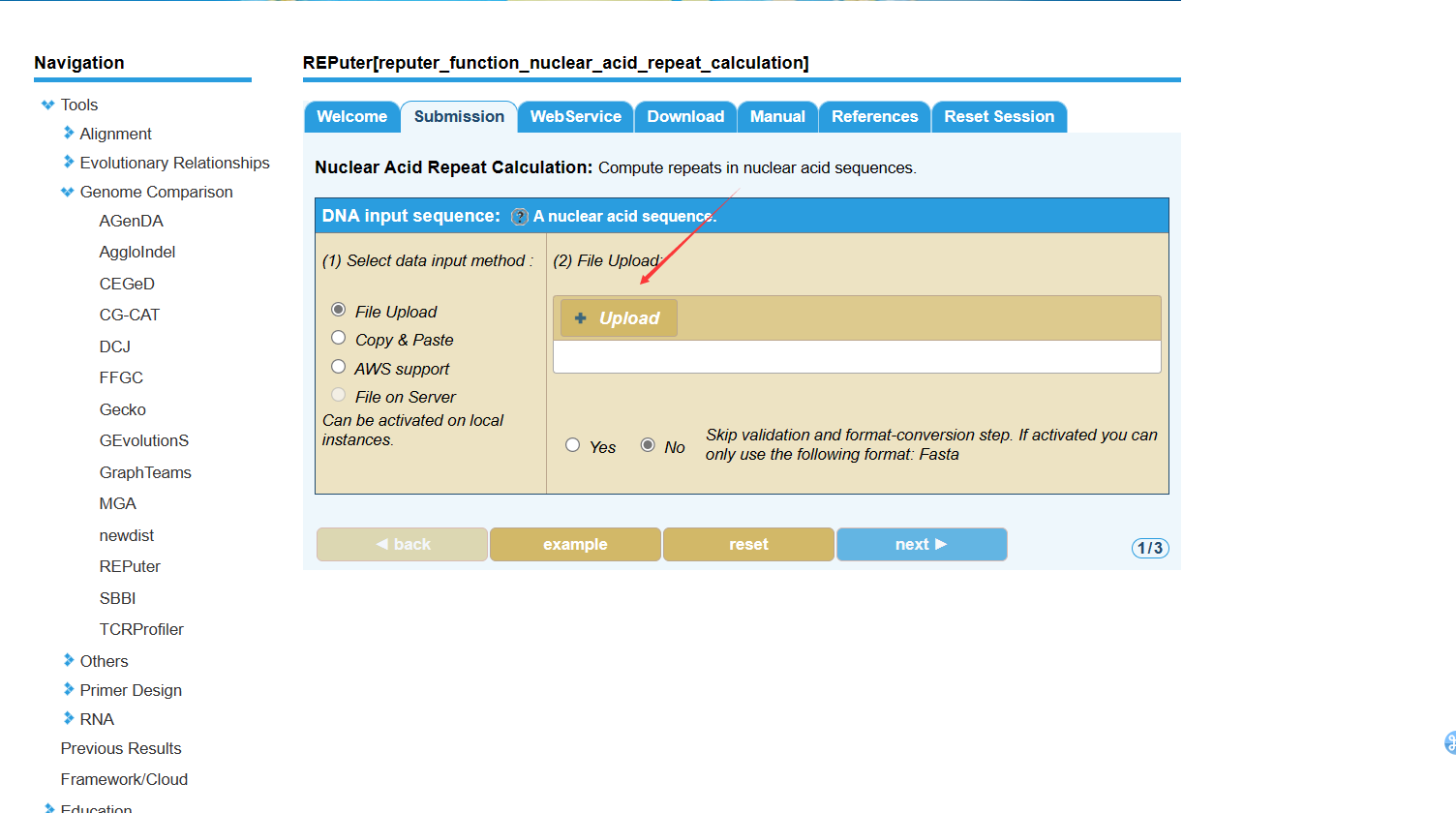
上传成功后点击next。
设置参数
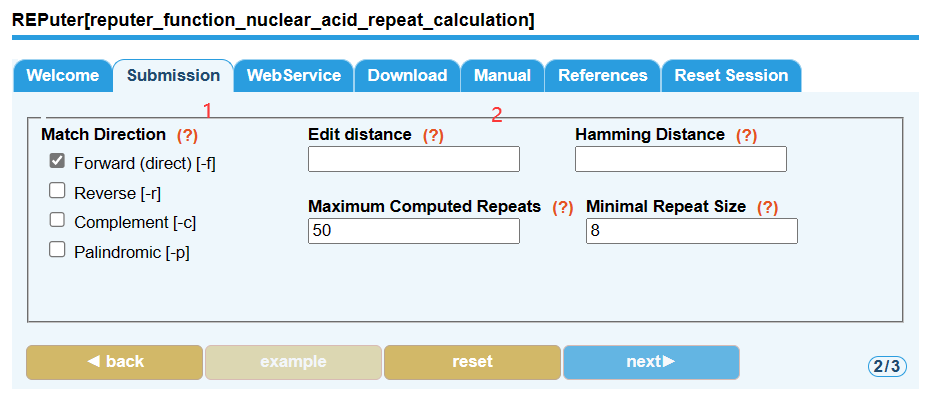
- 左边的Match Direction全都选上
- 右边我使用的参数:
Hamming Distance: 3
Maximum Computed Repeats: 5000
Minimal Repeat Size: 30
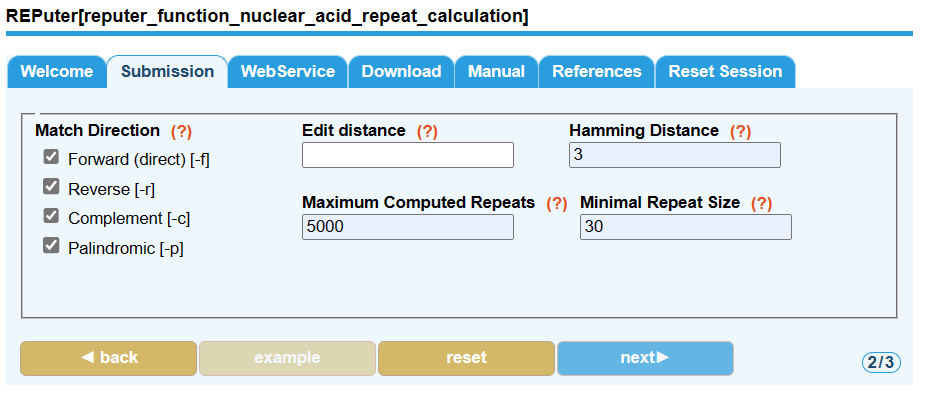
设置好之后,点击next。
分析并导出结果
点击 start calculcation
等它运行完,结果就出来了
然后自行下载文件即可。
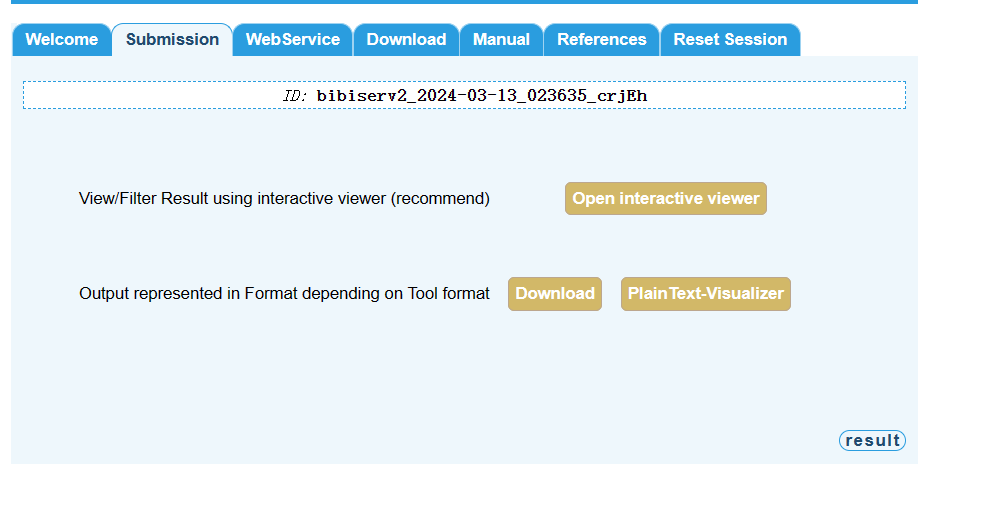
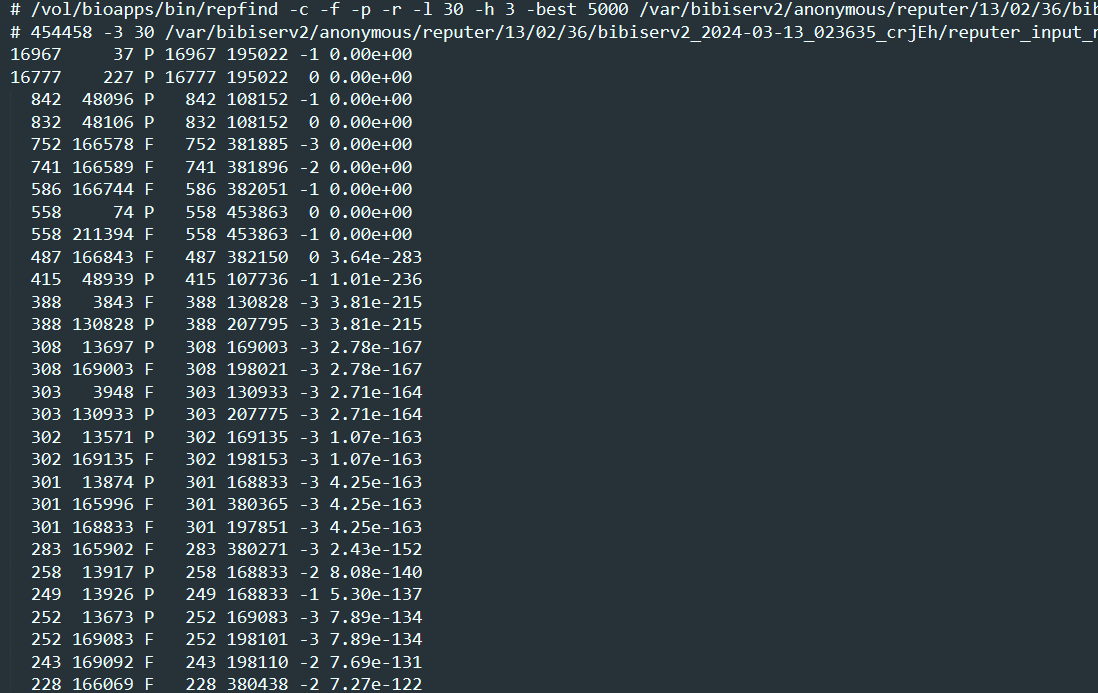
第二行 454458: 序列长度, 后面的-3,8 分别为maximum allowed distance, minimum repeat size
数据一共有7列:
- 重复序列1的长度
- 重复序列1的起始位置
- 重复序列类型:Forward (direct) [F]; Reverse [R]; Complement [C]; Palindromic [P]
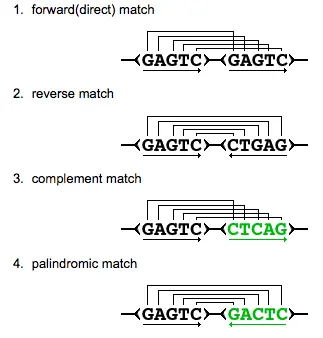
- 重复序列2的长度
- 重复序列2的起始位置
- 重复距离
- Evalue
结果优化
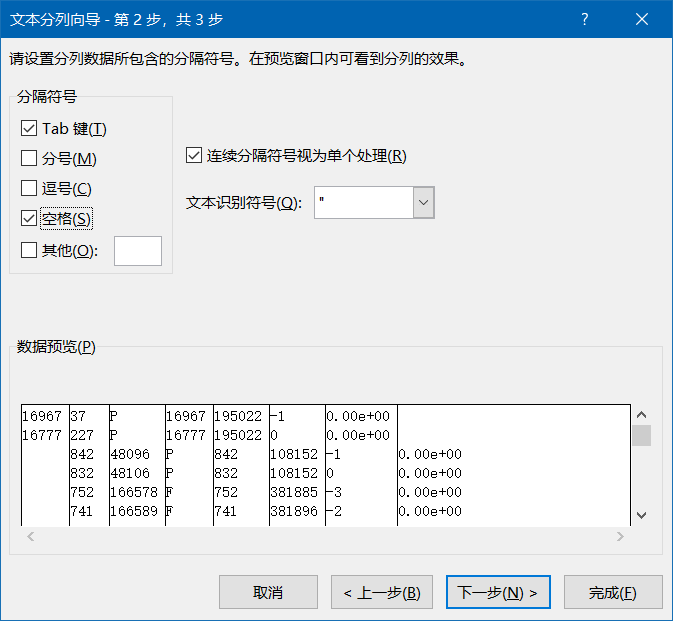
先把文件复制粘贴到Excel表格中,并对数据进行分列
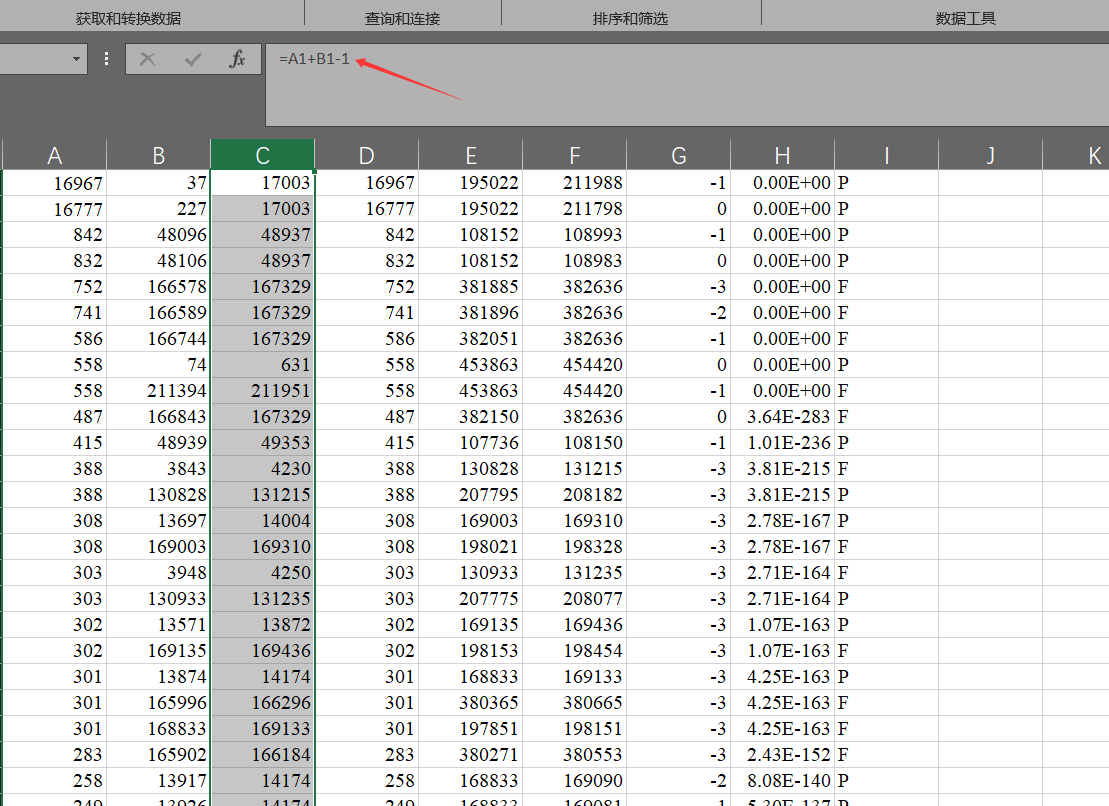
然后计算一下序列的终止位置。
终止位置-起始位置+1=序列长度
终止位置=序列长度+起始位置-1
然后将它们仅复制为值
用取并集的方式对序列进行整理。
这项工作比较繁琐,可以先对数据进行排序,然后突出显示重复值,这样会减轻一点工作量。
比如第一行和第二行数据,第二行数据明显在第一行数据里面,那么我们此时需要把两条序列合并,即删除第二行序列,不用管序列的类型。
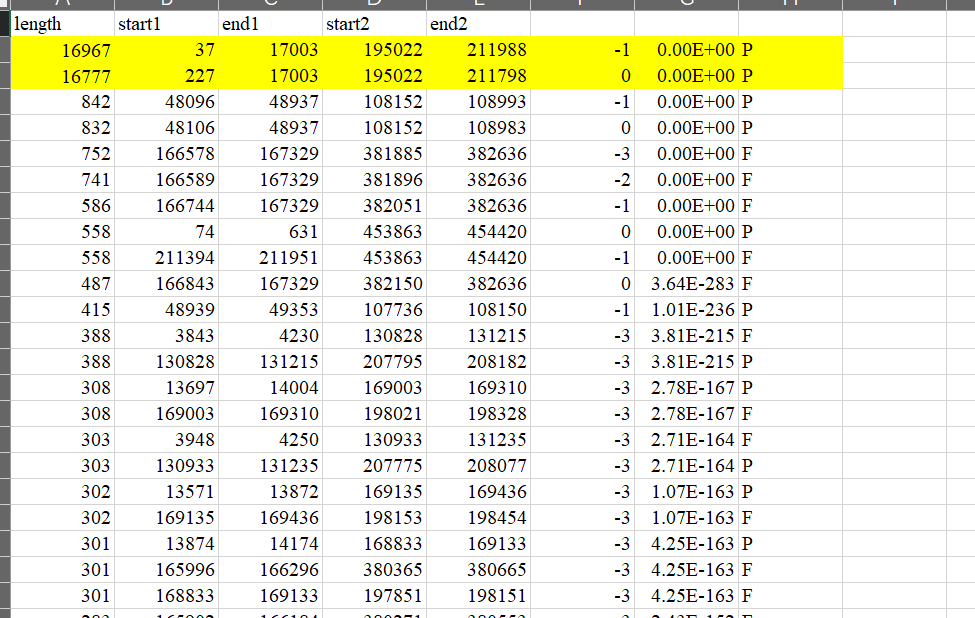
如果有多行数据相交的话,取这个区间的最大值和最小值,只保留一条数据。
比如这三行数据相交,序列1只要保留399379和399435,序列2只要保留421785和421841。若序列1长度和序列2长度不同,则相差不大即可。

这种自己和自己重复的也要去掉

注意:
- 相交的数据可能不在相邻几行中,要注意观察
- 只有序列1和序列2两条数据同时相交才可以合并。像图中的这两行数据就不可以合并。

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Sunning's Blog!
评论